About this site:
This website serves as a platform to showcase our project, which involves utilizing data science and machine learning to predict seizure activity from an electroencephalogram (EEG) dataset.
We’ve conveyed our project in different mediums such as through a Jupyter notebook and a research paper, but our objective in creating this site is to provide a user-friendly space where visitors can explore various aspects of our project in a comprehensive and engaging manner.
Through this website, we aim to provide access to the dataset, exploratory data analysis, visualizations, several machine learning models, and our findings- a unique version to allow users to gain a deeper understanding of our project. Through the display of charts, graphs, and other visualizations, users can delve into the intricate patterns and insights hidden within the EEG data. Moreover, the website will include informative descriptions, methodologies, and key findings, helping visitors grasp the significance of our project.
Ultimately, our goal is for this interactive site to provide an additional opportunity/version to explore our project and to communicate the value of our project, foster engagement and promote a deeper understanding of the EEG dataset and its implications.
Research Paper:
Our purpose in undertaking a personal scientific research paper as undergraduate scholars, is to explore machine learning modeling on a intuitive level, as well as apply use cases in a data science project focusing on an EEG dataset. This endeavor allowed us to communicate our experience in preprocessing, feature extraction, and model training on highly pertinent and deeply sensitive topics as health, especifically- neurological. The resulting research paper showcases this process, in particular- it documents our experiences using different machine learning models utilizing the EEG data and demonstrates the effectiveness and comparison of the various in pattern identification and outcome prediction. The paper allowed us to cultivate further critical thinking and scientific/technical communication skills, as well as allowed us to opportunity to work on sensitive information and highly valuable ideas for neuroscience in future EEG analysis and machine learning applications in more intimate levels.
General overview of dataset
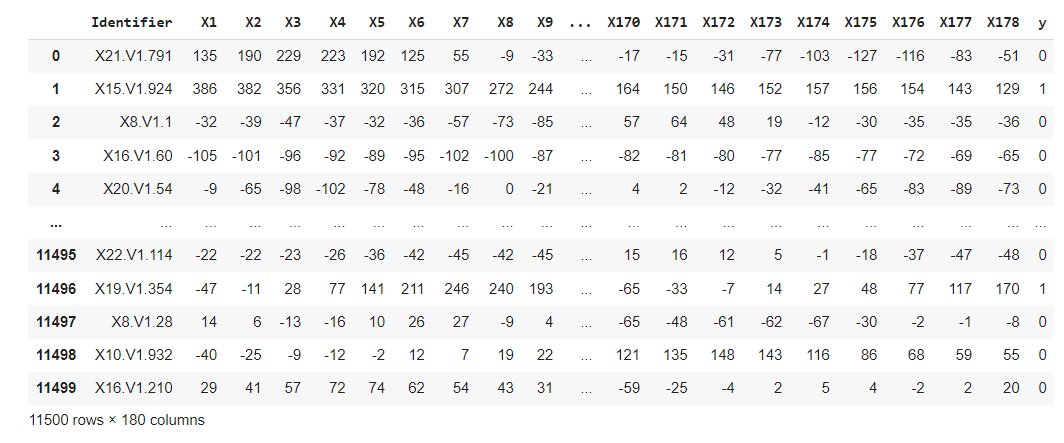
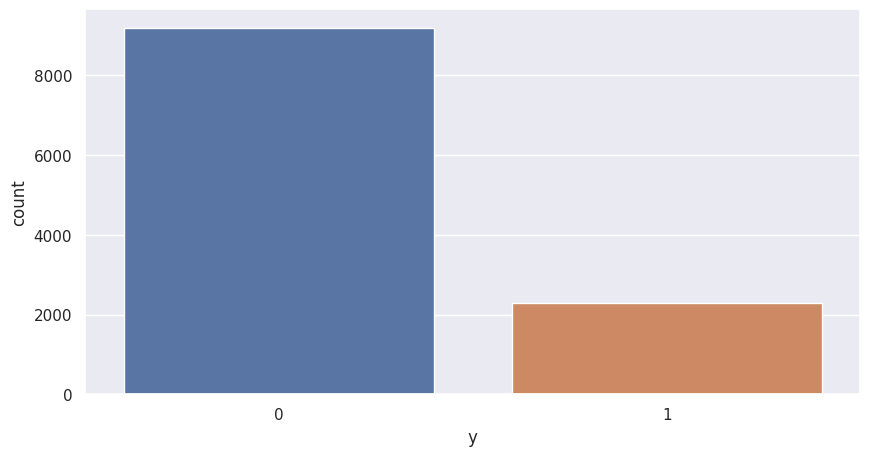
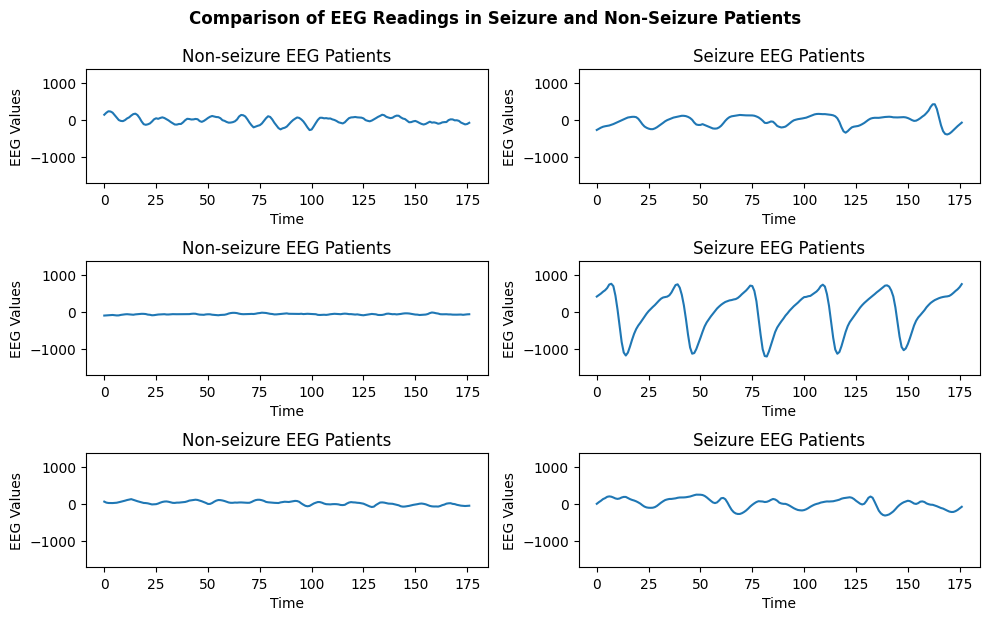
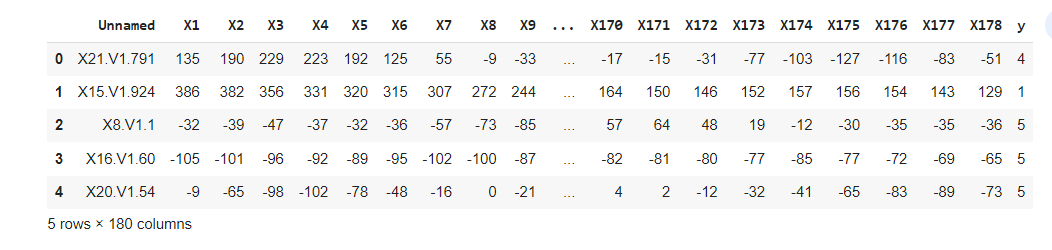
The Epileptic Seizure Recognition dataset, available on Kaggle, provides EEG data for the classification of seizures and non-seizure states. This dataset contains EEG recordings of 500 patients’ brain activity, with each recording consisting of 23.6 seconds sampled into 4097 data points. Each data point corresponds to the value of the EEG recording at a different point in time. These data points were split into 23 one-second chunks , where one chunk consisted of 178 data points. Each chunk is labeled with a category (1,2,3,4,5); category 5 meant that the patient’s eyes were open; category 4 meant that the patient’s eyes were closed; category 3 meant a recording of an area of the brain where the tumor was not present; category 2 meant a recording of an area of the brain where the tumor is present; category 1 meant a recording of seizure activity. Categories 2-5 are recordings of non-seizure activity.
Raw Data
Our winning model
Our goal is to determine the most optimal machine learning model among the observed options (Logistic Regression, Naive Bayesian, Decision Trees, K-Nearest Neighbor, Support Vector Machine) for accurately predicting epileptic seizures based on EEG signals. In the end, we concluded that the optimal model was the Support Vector Machine (SVM) model.
Logistic Regression
What is this model?
Logistic regression is a widely used statistical model in medicine, finance, and social sciences for binary classification tasks. It models the relationship between input features and the probability of an event using the sigmoid function, which maps real-valued numbers to probabilities between 0 and 1. The model's coefficients or weights are estimated through maximum likelihood estimation, aiming to maximize the likelihood of observed data.
Our application
In logistic regression, the output represents the probability of the positive class, and a decision threshold (usually 0.5) is chosen to classify instances accordingly. When applied to electroencephalogram (EEG) readings for seizure detection, logistic regression proves useful. EEG readings capture brain activity, and specific patterns can indicate the presence or absence of a seizure. In this scenario, the EEG readings serve as input features, and the binary outcome represents seizure presence. By training the logistic regression model, it learns the relationship between EEG readings and seizure probability, enabling predictions on new, unseen EEG data
Package use
reprocessing steps, such as feature extraction of relevant information like frequency bands or statistical measures, are commonly performed on the EEG readings before fitting the logistic regression model. After training, the model can predict the seizure probability for new patients based on their EEG readings. By selecting a decision threshold, the model's predictions can be converted into binary seizure/non-seizure classifications. However, it's important to note that logistic regression assumes a linear relationship between input features and log-odds. For more complex relationships, alternative techniques like polynomial logistic regression or advanced machine learning algorithms may be more suitable. Additionally, since logistic regression assumes independent observations, other modeling approaches like recurrent neural networks (RNNs) or long short-term memory (LSTM) networks might better capture temporal dependencies in EEG data.
Results
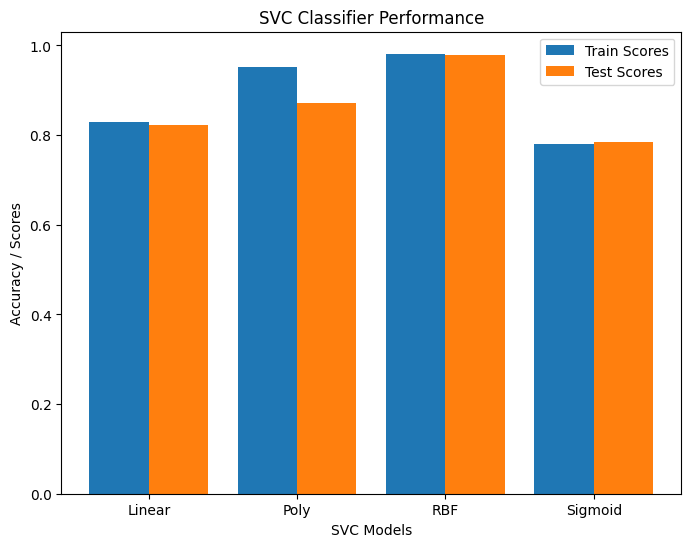
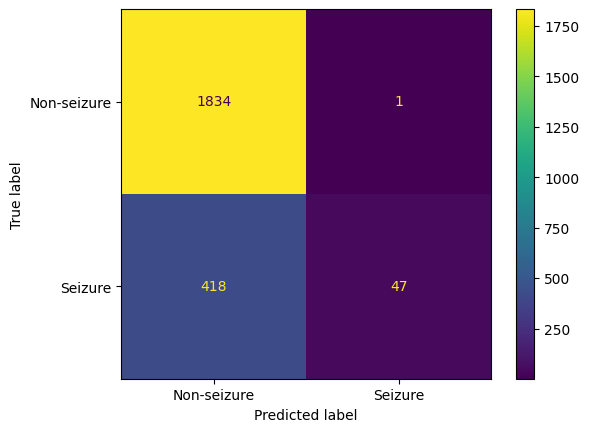
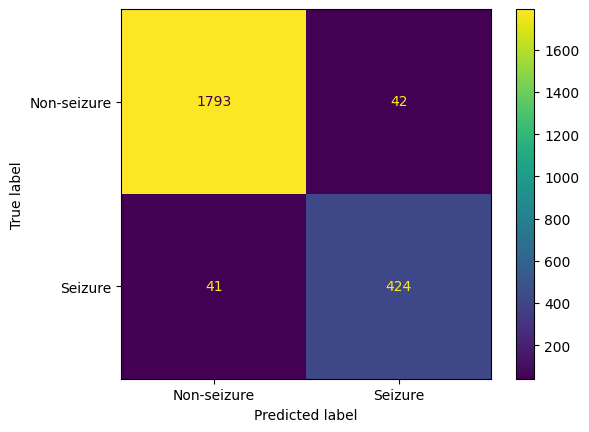
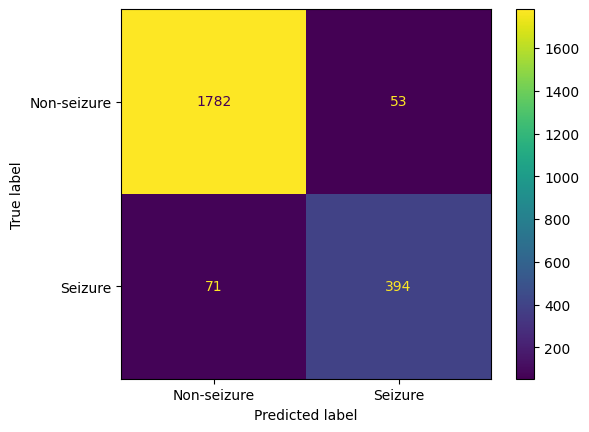
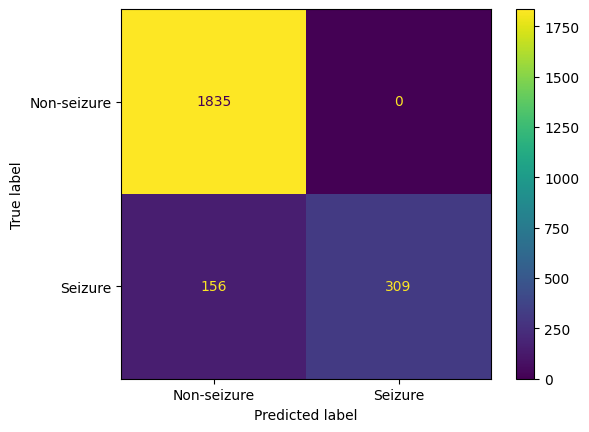
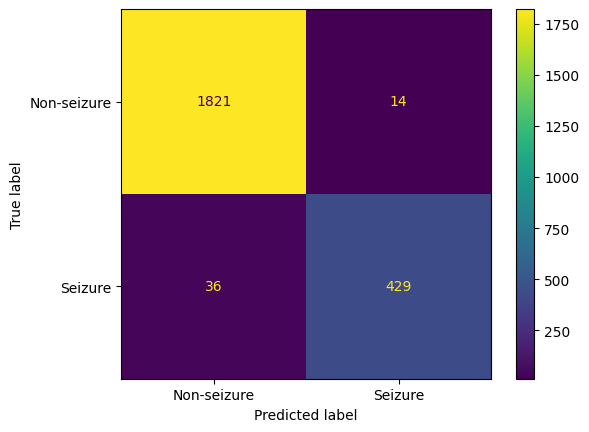
Given our goal is to identify the most optimal classification model for predicting epileptic seizures from EEG data, we define the "best model" as the one exhibiting the highest accuracy, highest F1 score, and the lowest number of type 2 errors (false negatives). In this context, a type 2 error refers to the situation where the model fails to identify seizure activity when a patient is experiencing an actual seizure. Given the critical nature of this scenario, minimizing type 2 errors is an imperative component of the best model. The above selection criteria ensures precise and reliable seizure predictions, striking a balance between correctly identifying positive instances and minimizing both false positives and false negatives. From the data above, we can see that the SVM is the best model that fits this criteria with an accuracy of 97.83%, F1 score of 94.49%, and a count of 36 for type 2 errors.
Naive Bayesian
What is this model?
Gaussian Naive Bayesian, also known as GaussianNB, is a probabilistic classification algorithm based on Bayes' theorem, which assumes independence between the features in the dataset. The algorithm is called "naive" because it makes the simplifying assumption that the features are independent of each other, which may not always be true in real-world datasets. GaussianNB is particularly well-suited for datasets with continuous features, as it models each feature using a Gaussian distribution. In classification, GaussianNB calculates the probability that a given data point belongs to a particular class based on the probability of the features, assuming that the features are normally distributed. This probability is then used to make a classification decision. GaussianNB is relatively fast and requires relatively small amounts of training data, making it a popular choice for classification problems with high-dimensional datasets.
Our application
GNB assumes that the features of the dataset are independent and normally distributed, which makes it particularly well-suited for modeling EEG data. In a seizure prediction project, the algorithm can be trained on a dataset of EEG recordings, with each recording labeled as either "seizure" or "non-seizure." The algorithm then uses the probability distribution of the features to calculate the probability that a given recording belongs to each class. By setting a threshold for the probability, the algorithm can make a prediction on whether the next recording is likely to be a seizure or not. GNB can be a powerful tool in seizure prediction projects, as it can analyze large amounts of EEG data quickly and accurately, potentially improving patient outcomes by allowing for earlier and more accurate diagnoses.
Package use
The Gaussian Naive Bayes classifier is a machine learning algorithm that is used for classification tasks. Specifically, it calculates the probability of a given data point belonging to a certain class based on the probability of the features in the dataset, assuming that the features are normally distributed and independent of each other.
In order to make a classification decision, the algorithm first calculates the probability that a data point belongs to each class based on the features, using Bayes' theorem. It then assigns the data point to the class with the highest probability.
The "naive" assumption in the algorithm is that the features are independent of each other, which may not always be true in real-world datasets. Despite this simplifying assumption, the Gaussian Naive Bayes classifier can perform well on a wide variety of classification tasks and is particularly well-suited for datasets with continuous features.
Parameters
Prior probabilities: The prior probabilities represent the probability of each class occurring in the dataset before any evidence is taken into account. These probabilities can be estimated from the training data or set manually.
Class conditional probabilities: The class conditional probabilities represent the probability of each feature given each class. In Gaussian Naive Bayes, these probabilities are modeled using a Gaussian distribution with mean and variance estimated from the training data for each class and feature.
Results
Given our goal is to identify the most optimal classification model for predicting epileptic seizures from EEG data, we define the "best model" as the one exhibiting the highest accuracy, highest F1 score, and the lowest number of type 2 errors (false negatives). In this context, a type 2 error refers to the situation where the model fails to identify seizure activity when a patient is experiencing an actual seizure. Given the critical nature of this scenario, minimizing type 2 errors is an imperative component of the best model. The above selection criteria ensures precise and reliable seizure predictions, striking a balance between correctly identifying positive instances and minimizing both false positives and false negatives. From the data above, we can see that the SVM is the best model that fits this criteria with an accuracy of 97.83%, F1 score of 94.49%, and a count of 36 for type 2 errors.
Decision Tree
What is this model?
# Decision Tree
A decision tree (DT) is a supervised machine learning algorithm used for both classification and regression, it uses a set of rules to make a decision similarly to how a human would make decisions. The nodes of a DT are decision nodes based on a particular feature in the dataset, each node branches into two or more outcomes based on the decision node. DTs can be considered a greedy top-down algorithm. At each node, we want to either minimize the Gini Index or maximize Information Gain.
Our application
We decided on a DT classifier that uses the Gini Index measure because:
- 1. DTs are nonparametric, so it works well with our data since it does not follow a specific distribution
- 2. Gini Index DTs are often used to classify target variables that are binary, which aligns with our goal of classifying seizure vs non-seizure patients
- 3. Gini Index DTs are computationally more efficient than Entropy DTs
Package use
DTs can use Gini Index or Entropy+Information Gain to measure the impurity of a split at each node.
- Gini Index: measures the probability of a random instance (datapoint) being misclassified based on according to distribution of labels in the subset. Gini Index can range from 0 to 1; a lower Gini Index indicates a lower likelihood of misclassification, making it a better measure of impurity.
- Entropy: measures the degree of randomness at a particular node. Entropy can range from 0 to 0.5; a smaller Entropy indicates the subset of datapoints have higher puurity/homogeneity.
- Information Gain: the difference between the entropy of the parent node and the average of the entropies of its child nodes.
Results
Given our goal is to identify the most optimal classification model for predicting epileptic seizures from EEG data, we define the "best model" as the one exhibiting the highest accuracy, highest F1 score, and the lowest number of type 2 errors (false negatives). In this context, a type 2 error refers to the situation where the model fails to identify seizure activity when a patient is experiencing an actual seizure. Given the critical nature of this scenario, minimizing type 2 errors is an imperative component of the best model. The above selection criteria ensures precise and reliable seizure predictions, striking a balance between correctly identifying positive instances and minimizing both false positives and false negatives. From the data above, we can see that the SVM is the best model that fits this criteria with an accuracy of 97.83%, F1 score of 94.49%, and a count of 36 for type 2 errors.
k-Nearest Neighbor (kNN)
What is this model?
K-Nearest Neighbors (KNN) is a simple yet powerful non-parametric supervised learning algorithm used for classification and regression tasks. It operates on the principle that data points with similar features are likely to belong to the same class or have similar outputs. KNN has a wide range of applications, including healthcare, recommendation systems, and pattern recognition.
Our application
The main parameters in KNN are K, which determines the number of neighbors considered when making predictions, and the distance metric used to measure the similarity between data points. When applying KNN to seizure prediction based on EEG readings, the preprocessed EEG features are considered as inputs, and the class labels (seizure or non-seizure) are used to make predictions based on the K nearest neighbors.It is important to carefully choose the values of K and the distance metric when applying KNN to seizure prediction to ensure optimal performance. The selection of K should be based on the specific dataset and problem at hand, and the choice of distance metric should be aligned with the nature of the EEG features and the underlying assumptions of the data.
Package use
The KNN algorithm works by storing the entire training dataset as the model and using it to make predictions on new, unseen data points. When predicting the class or output of a new instance, KNN looks at the K nearest neighbors in the training dataset, where K is a user-defined parameter. The prediction is then based on the majority class or the average of the outputs of those K neighbors.
Results
Given our goal is to identify the most optimal classification model for predicting epileptic seizures from EEG data, we define the "best model" as the one exhibiting the highest accuracy, highest F1 score, and the lowest number of type 2 errors (false negatives). In this context, a type 2 error refers to the situation where the model fails to identify seizure activity when a patient is experiencing an actual seizure. Given the critical nature of this scenario, minimizing type 2 errors is an imperative component of the best model. The above selection criteria ensures precise and reliable seizure predictions, striking a balance between correctly identifying positive instances and minimizing both false positives and false negatives. From the data above, we can see that the SVM is the best model that fits this criteria with an accuracy of 97.83%, F1 score of 94.49%, and a count of 36 for type 2 errors.
Support Vector Machine (SVM)
What is this model?
SVMs are a set of supervised machine learning algorithms used for classficiation and regression. Support Vector Classifier (SVC) is an implementation of SVMs specifically used for classification problems. SVCs aim to find the optimal hyperplane that separates the datapoints into two classes with the maximum margin.
Margin: the distance between the hyperplane and the closest data points from each class.
Our application
We decided to use a SVC because:
Our dataset has a large number of features (178 predictors) and SVCs can handle datasets with high-dimensional spaces.
Our target variable is binary (seizure or non-seizure), so no additional transformations are needed to train SVC
Package use
The SVC function allows users to create an SVM model and customize its parameters, such as the type of kernel used, regularization parameter, and class weighting. It can handle both binary and multiclass classification problems and provides methods for training the model on a given dataset and making predictions on new data.
Results
Given our goal is to identify the most optimal classification model for predicting epileptic seizures from EEG data, we define the "best model" as the one exhibiting the highest accuracy, highest F1 score, and the lowest number of type 2 errors (false negatives). In this context, a type 2 error refers to the situation where the model fails to identify seizure activity when a patient is experiencing an actual seizure. Given the critical nature of this scenario, minimizing type 2 errors is an imperative component of the best model. The above selection criteria ensures precise and reliable seizure predictions, striking a balance between correctly identifying positive instances and minimizing both false positives and false negatives. From the data above, we can see that the SVM is the best model that fits this criteria with an accuracy of 97.83%, F1 score of 94.49%, and a count of 36 for type 2 errors.
Citations
- Epileptic Seizure Recognition dataset. (n.d.). Kaggle. Retrieved from https://www.kaggle.com/datasets/harunshimanto/epileptic-seizure-recognition
- Bukovsky, I. (n.d.). Electrical activity of the brain. Retrieved from http://users.fs.cvut.cz/ivo.bukovsky/PROJEKT/Data/Realna/BIO/EEG/reference/PRE61907.pdf
- Andrzejak, R. G., Lehnertz, K., Mormann, F., Rieke, C., David, P., & Elger, C. E. (2001). Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: dependence on recording region and brain state. Phys Rev E Stat Nonlin Soft Matter Phys, 64(6 Pt 1), 061907. https://doi.org/10.1103/PhysRevE.64.061907
- Ahmadi, N., Amiri, M., Abbasi, H., Pooyan, M., & Rostami, R. (2020). EEG-Based Classification of Epilepsy and PNES: EEG Microstate and Functional Brain Network Features. Brain Informatics, 7(1), 8. https://doi.org/10.1186/s40708-020-00106-2
- Atkinson, M. (2010). How to interpret an EEG and its report - Neurology. Wayne State University. Retrieved from https://neurology.med.wayne.edu/pdfs/how_to_interpret_and_eeg_and_its_report.pdf
- Naive Bayes. (n.d.). scikit-learn. Retrieved from https://scikit-learn.org/stable/modules/naive_bayes.html
- Decision Trees. (n.d.). scikit-learn. Retrieved from https://scikit-learn.org/stable/modules/tree.html#tree
- Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2013). Bayesian Data Analysis (3rd ed.). CRC Press.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum
Our Dataset
The detection and diagnosis of epileptic seizures is an important area of medical research, as timely detection and treatment can greatly improve patient outcomes. The Epileptic Seizure Recognition dataset, available on Kaggle, provides EEG data for the classification of seizures and non-seizure states. This dataset contains 5,000 recordings from 5 different patients, with each recording consisting of 23.6 seconds of EEG data sampled at 178 Hz. The data is labeled as either "seizure" or "non-seizure", and there are 5 different sets of data for different patients.
Further Context
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum
Key Terms
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum
Further dataset explorations and interesting tidbits
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum
Who are we?
As a data science project, the Epileptic Seizure Recognition dataset provides an opportunity to explore the use of machine learning models for the classification of EEG data. This could involve feature engineering, model selection, and evaluation to develop an accurate and reliable classifier for epileptic seizures. The project also presents challenges related to the small size of the dataset and the need to handle sensitive medical data with care.
Why this is important?
Data science is bringing innovation to medical areas in several ways, including predictive models for disease diagnosis and treatment, medical imaging analysis, and drug development. With the power of machine learning and advanced analytics techniques, data science can analyze complex datasets to identify patterns and relationships that would be difficult for humans to detect. This technology has the potential to improve the accuracy and speed of diagnoses, track disease progression, and develop new treatments for a variety of diseases. The innovation of data science in medical areas has the potential to significantly improve patient outcomes, accelerate medical research, and address some of the most pressing healthcare challenges.